Discovery and Optimization of Enantioselective Catalysts through Chemoinformatics
The development of synthetic methods in organic chemistry has historically been driven by Edisonian empiricism. Catalyst design is no exception wherein experimentalists attempt to qualitatively recognize patterns in catalyst structures to improve catalyst selectivity and efficiency. However, this approach is hindered by the inherent limitations of the human brain to find patterns in large collections of data, and the lack of quantitative guidelines to aid catalyst selection. Chemoinformatics provides an attractive alternative for several reasons: no mechanistic information is needed; catalyst structures can be characterized by 3D-descriptors which quantify the steric and electronic properties of thousands of candidate molecules; and the suitability of a given catalyst candidate can be quantified by comparing its properties to a computationally derived model on the basis of experimental data. The ability to accurately predict a selective catalyst using a set of non-optimal data remains a Grand Challenge of machine learning with respect to asymmetric catalysis.
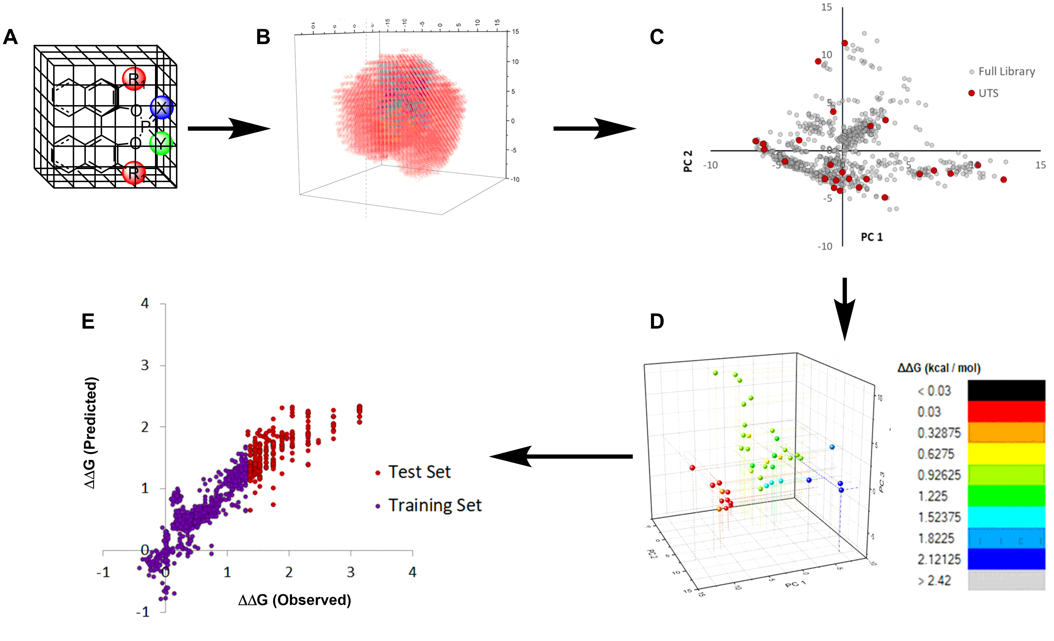
This lecture will describe a newly developed, chemoinformatic workflow that consists of the following components: (i) construction of an in silico library of a large collection of conceivable, synthetically accessible catalysts of a particular scaffold; (ii) calculation of robust chemical descriptors for each scaffold (iii) selection of a representative subset of the catalysts in this space. This subset is termed the Universal Training Set (UTS), so named because it is agnostic to reaction or mechanism. (iv) Collection of the training data, and (v) application of modern machine learning methods to generate models that predict the enantioselectivity of each member of the in silico library. These models are evaluated with an external test set of catalysts. The validated models can then be used to select the optimal catalyst for a given reaction.